Create a Telegram Bot to Help You Learn a New Language
Web scraping and Google Text-to-Speech API to the rescue

Introduction
Since I have a lot of free time at home due to the Covid-19 outbreak, I tried to learn a new skill. Last week I decided to start learning Hangeul (Korean alphabet).
In order to read and speak Korean language you need to understand Hangeul first, but sometimes the way Hangeul is written is different from the way we pronounce it.
One way to learn how to pronounce certain Korean word is by copying those word in Google Translate and listening to how to pronounce it.
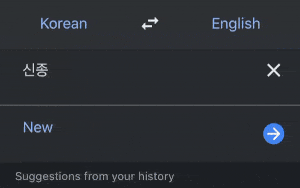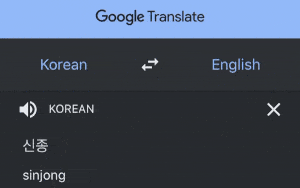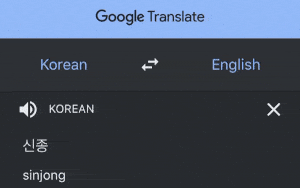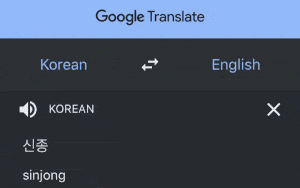
But this seems exhausting since we need to constantly move from one app to another and do some copy-paste.
In this tutorial, we are going to build a telegram bot that will help us achieve our goal (learning how to pronounce Korean words) in an easy way.
We are going to scrape a Korean website (in this case BBC Korea) → get a few words → to create audio files on how to pronounce them using Google Text-to-Speech API → save it. The bot then will send the word and the audio file to help us learn how to read Hangeul and pronounce it.
Here is the example of a bot that we are going to create.
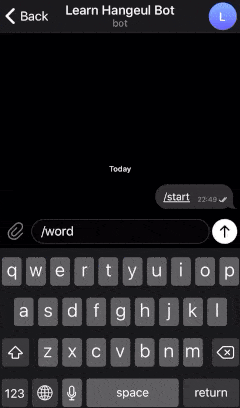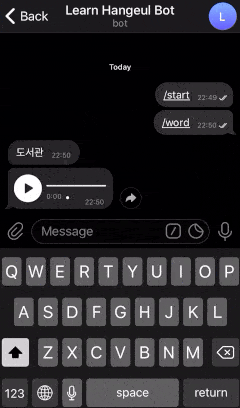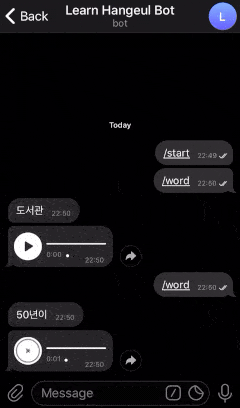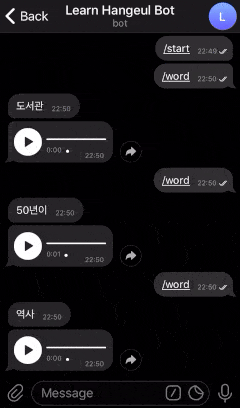
Looks cool right? Let’s get started!
PS: If you are learning other languages, you can also modify the script to learn how to pronounce certain words in your preferred language.
Getting Started
1. Install the libraries
We are going to use Requests and BeautifulSoup to scrape the website, Google Text-to-Speech API to create the audio on how to pronounce the Hangeul, Pandas to help us manipulate the data, and python-telegram-bot to create the bot.
pip install requests beautifulsoup4 google-cloud-texttospeech pandas python-telegram-bot
2. Enable Google Text-to-Speech API and set a credential
Go to the Google Text-to-Speech API guidelines. In the Before you begin section, follow the guideline until you finish setting the environment variable in step 5.
After this step, you should have a credential in the format of .json (for this tutorial, let’s name it creds.json) and you should have the environment variable GOOGLE_APPLICATION_CREDENTIALS points to your creds.json path.
3. Create a new bot in BotFather
If you want to make a bot in Telegram, you have to register your bot first before using it. When we register our bot, we will get the token to access the Telegram API.
Go to the BotFather, then create a new bot by sending the /newbot command. Follow the steps until you get the username and token for your bot. You can go to your bot by accessing this URL: https://telegram.me/YOUR_BOT_USERNAME and your token should looks like this.
704418931:AAEtcZ*************
Write the Program
We are going to create two scripts for this tutorial. The first one is for preparing the dataset (scrape the website, create the audio, and save the data), the second one is for running the bot.
1. Prepare the Dataset
Let’s import the necessary dependencies for this task.
from google.cloud import texttospeech
from bs4 import BeautifulSoupimport pandas as pd
import requests
import re
We are going to scrape the specific page from BBC Korea which is the Top News Page and get the news titles.
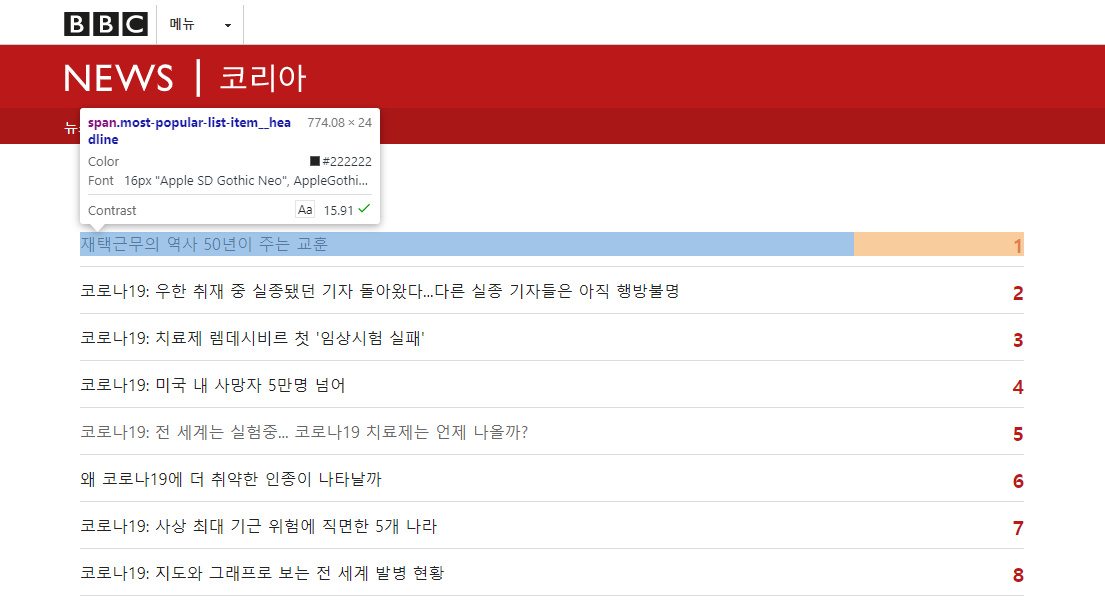
If we take a look from Google Chrome inspect element, each title is wrapped in the span element and most-popular-list-item__headline class. This is the code to scrape that specific element using BeautifulSoup.
url = 'https://www.bbc.com/korean/popular/read'
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
titles = soup.findAll('span',
{'class': 'most-popular-list-item__headline'})
Now let’s iterate through titles, get the news title, split it into words, and append it in a list. We are using regex to remove any punctuation in the title.
result = []for title in titles:
title = re.sub(r'[^\w\s]', '', title.text)
words = title.split()
result += words
Wrap the codes above into a function called get_hangeul so that your code looks like this.
Note that we return set(result) because we want the list to have unique values, and we can achieve that using Python Set.
After we get the Hangeul, we are going to use Google Text-to-Speech API to create the audio file for each word and save it in a folder called audio.
I used the code from Google Text-to-Speech quick start guidelines here in the Create audio data section. Let’s modify it a little and wrap the code into create_audio function that takes text (Korean word) and language (the default is ko-KR which is Korean), and will save the audio in the audio folder.
Now create the main function that calls the get_hangeul, iterate through its result and save the audio file and also save the list of Korean words in .csv format called dictionary.csv.
words = get_hangeul()for word in words:
create_audio(word)dictionary = pd.DataFrame(words, columns=['word'])
dictionary.to_csv('dictionary.csv', index=False)
Using those main function, wrap all of the codes above and save it as dataset.py. Your file should look like this.
Cool! Run the script from the terminal (do not forget to create folder audio first in the same path as dataset.py).
python dataset.py
After running the script, you will see now, we have .mp3 files in the audio folder and dictionary.csv.
Great! The dataset is ready, let’s create the bot.
2. Create the Telegram Bot
How our bot works is pretty simple. Every time the user sends /word command, we are going to take one random word from dictionary.csv, and send it with the corresponding .mp3 file.
First, import the libraries and set the logging function (this is for debugging your bot if it encounters some errors).
from telegram.ext import Updater, CommandHandlerimport pandas as pd
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(levelname)s - %(message)s')
logger = logging.getLogger()
logger.setLevel(logging.ERROR)
Let’s create a function for our bot’s main task. In this function, the bot will read the dictionary.csv file, randomly picking one word, then send the word and the audio file back to the user and wrap it in a function called send_word.
Now create a main function to run the bot.
When we write CommandHandler('word', send_word)), that means every time user sends command /word to the bot, it will run the send_word function.
Combine all of those codes in one file called main.py. Your file should look like this.
Now you can run the main.py file in the terminal.
python main.py
If everything runs perfectly, you should see your bot sending back the word and its audio after you send the/word command to the bot.
Congratulations! It is not difficult, right? Now you have a telegram bot that helps you learn a new language, cool!
Further Development
I know this is far from perfect, so here is the list of recommendations if you want to develop the bot more and make it cooler.
- Using cron job or python-telegram-bot Job Queue to automatically scrape the website so the dictionary will expand.
- Add features where the bot will send the word and we have to send our voice (using voice notes) pronouncing it, then using Google Speech-to-Text API we are going to verify whether we pronounce it right or wrong.
- Many more…
You can visit my GitHub profile to get the code or check the working bot in here.
Please do not hesitate to connect and leave a message in my Linkedin profile if you want to ask about anything.
If you have an interest in data science or machine learning, you might want to read my post on building sentiment analyzer and automating task using Python.
Once again, thank you and good luck! 🙂
Ten articles before and after
NFTs for Telegram (and Chat) Group Memberships – Best Telegram
How to Share Music On Telegram ? – Best Telegram
Join Our Telegram Announcement Channel – Best Telegram
Hiveterminal: Telegram Restructuring – Best Telegram
Russia’s Telegram Ban Isn’t Just an Attack on Privacy – Best Telegram
Telegram Channels for Technical Writers – Best Telegram
Telegram Update: Official Language Groups – Best Telegram
AIOZ Network: Get ready for our Telegram AMA tomorrow – Best Telegram
The OLPORTAL Telegram Community is Now 10K Strong! – Best Telegram
Highlights From The MEDIA Protocol And Quadrant Protocol Telegram AMA – Best Telegram