The art of indexing +1PB data on Telegram
In this article an overview of a collector architecture based on Telegram will discuss.Introduction
Yes.. that’s true. In the last 2 years, I have crawled channels and groups to gather more than 1PB of movies and series on Telegram! Besides my crawler architecture, this article discusses Telegram’s capacity and features. Before reading, feel free to search some films or series in my bot: https://t.me/EzPzFileBot.

What is Telegram?
It’s the world’s best instant messenger! While it may not be the biggest, it is definitely the best! Telegram lets you text everyone just like WhatsApp, Viber, Facebook Messenger, etc. It contains features such as Video calls, Voice calls, Public/Private Channels/Groups, and Bots! Upon request, I can explain some of Telegram’s features and functionality!
Telegram client is an open-source project due to its flexible infrastructure and back-end system. This means that there are many different available Telegram clients . MTPoroto is used to communicate with clients. Nikolai Durov, the co-founder of Telegram, has written this protocol himself. Telegram, on the other hand, includes bots that perform some functions. If you want to use Telegram bots, you need to communicate via the Restful HTTP API. More information about them is here.
In addition, Telegram File Storage is a great feature! It is free and unlimited. You may upload up to 2GB of files as a client, but bots are limited to 20MB. As a result, you cannot upload anything via bots. However, there are a lot of projects that use MTProto and the bot API to integrate this feature to increase the amount of uploading files. I do not utilize this specific functionality because I need another feature for forwarding files!
Main Idea
Basically, the system crawls channels/groups and forwards their files to a different location. The main bot parses the message attributes and saves them to Postgresql. To improve search speed and performance, Elasticsearch is used.
A collector is sometimes a better choice than a producer. Many public and private Telegram channels provide movie/series files to their users. Users could not find and search the files and movies with an integrated bot or channel despite this. It is the primary value proposition of bots on Telegram.
Instead of uploading more files on Telegram and spending a lot of time and money, it is better to use other data to collect them and provide added value.
Telegram has a distributed file storage to help clients and bots to manage files. By obtaining a file’s file_id, bots can send it to users even if the file has been deleted or cannot be accessed through clients due to copyright fragments.
So, the EzPzFile bot is an integrator to crawl channels and groups to collect and save files.
The Architecture
In this section, I illustrate the architecture of the system.
Crawlers
Telegram Bots do not have access to channels’ and groups’ data until they are their admin. So, the programmer cannot collect data via bots. On the other hand, clients (client is an account on Telegram with a valid phone number) have access to see, forward (until the last update 🙂 ), and upload files up to 2 GB. So, it is widespread that programmers write a bot on top of MTProto utilizing the client’s features. However, this system is not using typical ways. The bot and the crawler are separated, and the bot controls the crawler to get the data and requests the crawler to forward files passing the rules and conditions to be added to the bot. You can see the sequence diagram at the bottom:
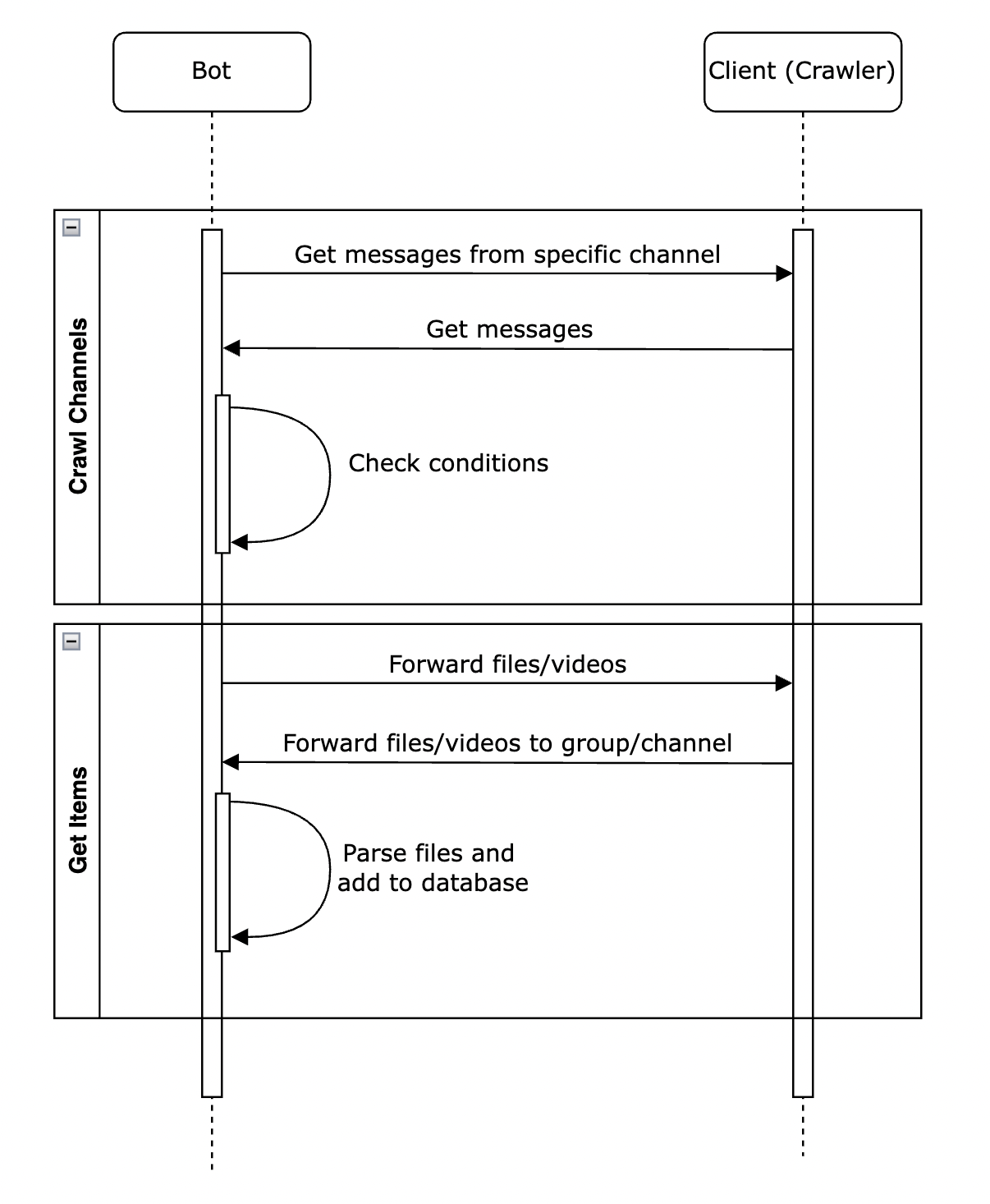
You can do it so easily! For controlling channels, the bot must be able to index channels in the first stage. In a repetitive state machine, the crawler requests the latest crawled messages. The response JSON contains new messageIDs and attributes. In a powerful engine, message details are analyzed, and files are sent to a private channel or group. With this trick, the bot can now index the files/videos that it has access to. Following this, the bot stores the message-id of the latest crawled message for use in the next process.
Bots cannot access to files in the public channels/groups until they are admin! So, it is necessary to send them files until they can index them.
Parsing
The process of parsing file names and attributes takes a long time. Each file, on average, takes 1 to 2 seconds, and in each batch of operations, the system faces about 1k files. So, it needs to be an async system. As a result, we separate the gateway and authentication process from the main process. Like many systems, the authentication and minimum condition checking happen at the gateway layer. Upon validation, tasks are placed on the broker (RBQ) to be continued.
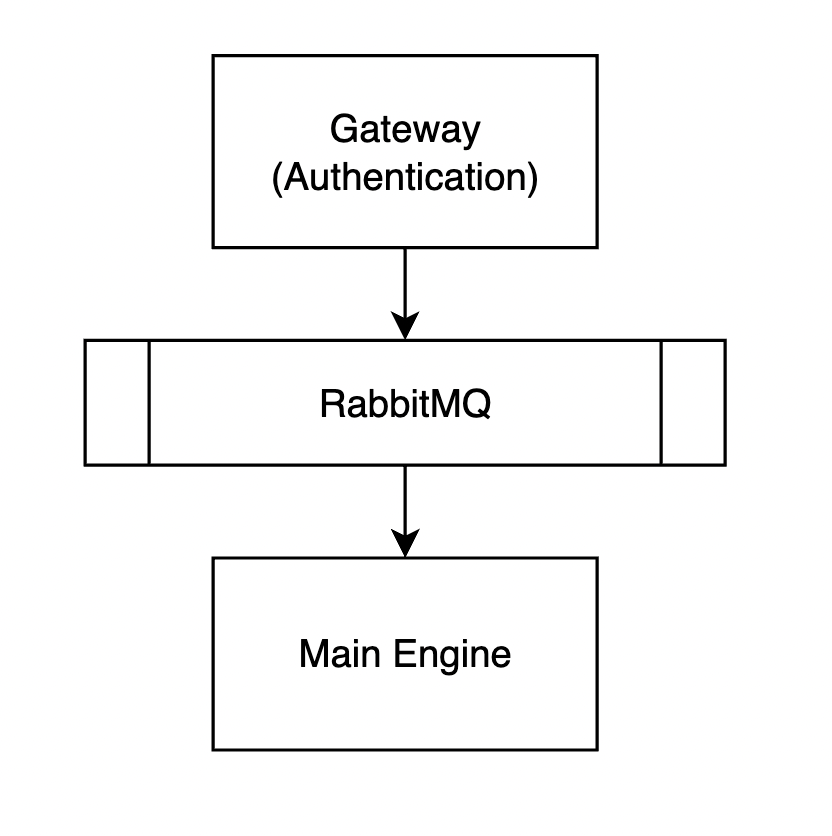
Storing
The main engine extracts the attributes, name, and other necessary processes that connect the file/video to a movie/series. The states containing * have their algorithm and diagram. The process of the main engine is illustrated in this diagram.
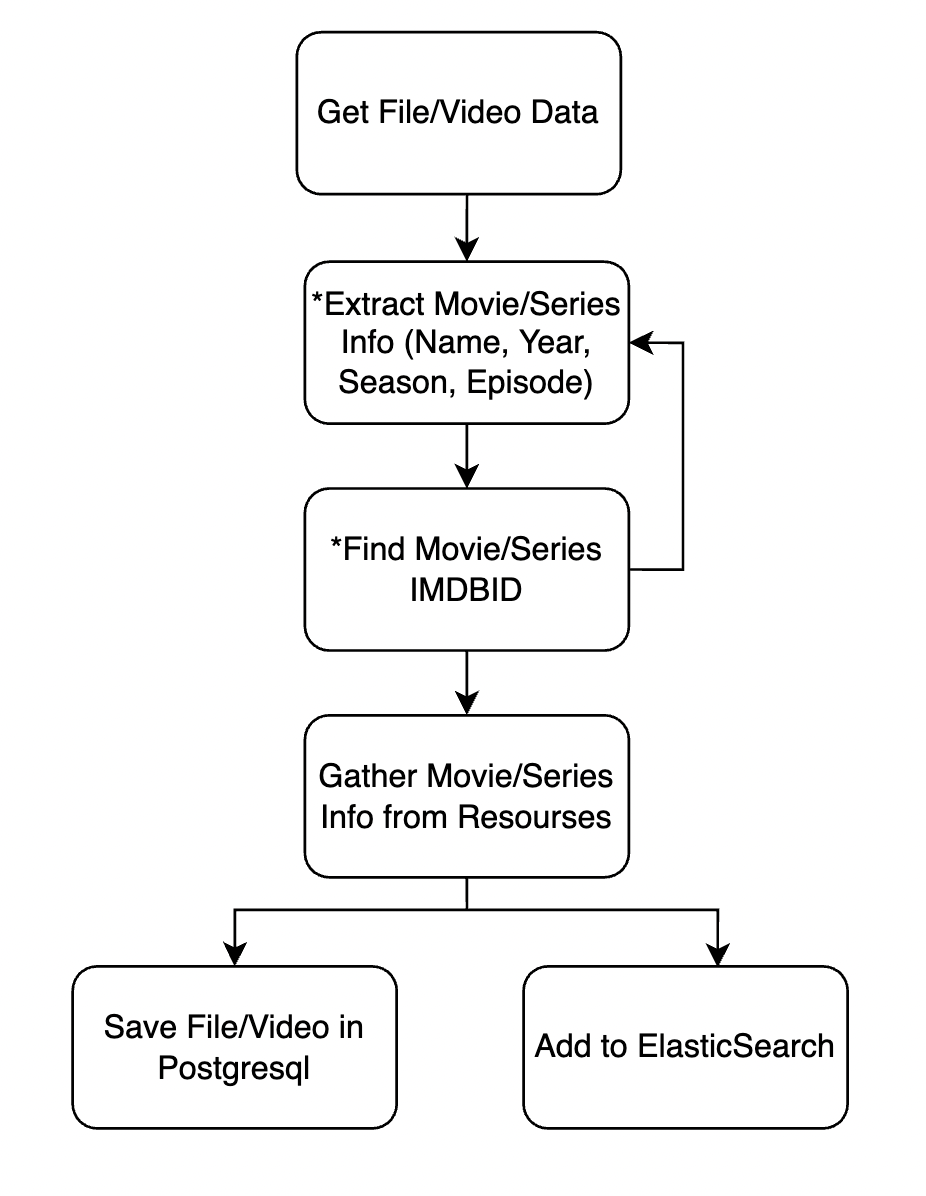
Some algorithms extract movie/series names and other attributes. Sometimes, it gets feedback from the next stage (find movie/series imdb_id) to ensure accuracy and the movie’s kind and name (by similarity check).
Finding a movie/series’ IMDBID is the most critical stage of processing. IMDBID is used to identify all system components, and the name of the movie must be labeled precisely. So, the system uses IMDB search, its Elasticsearch, TMDB, and their combination.
Elasticsearch contains files/video data such as file_name, caption, and other attributes. Also, after finding the right movie for file/video, the whole movie’s info is indexed in the elastic until it can be searchable for users. So, the user can search files by casts, crews, aka title, etc.
Why this architecture?
I know it is straightforward and obvious. But, it has a lot of details and optimization. I implement this architecture only on a 4 GB server and handle more than 10k users DAU. Also, it is scalable and prunes to be blocked by Telegram or data-center. Each company can complain about the content and ban the bot if it violates copyright law. But, the main bot can be replaced easily by another bot, the client crawler can be replaced or scaled to more than one crawler, and the async system can handle a vast amount of data.
I lost all of my data two times due to Telegram’s policy and changing its data centers! Bots’ FileIDs are universal without any expiration time. So, this arch gets mature over time.
Conclusion
This architecture can handle a significant stream of data and users. 1PT data is crawled and not uploaded to Telegram! I do not cover a lot of details and Telegram policy, especially the reason for using some of my components. I may explain some of the parts of the system deeply.
This is my mature architecture, and I am open to listening to any feedback or revisions about my work or my article! Please add a comment, and I will answer you or contact you if you want anything :))
Start the bot and access to +1PT data for free https://t.me/EzPzFileBot
Ten articles before and after
Telegram in Business: How to Use the Messenger to Increase Sales – Telegram Group
Stop posting your emails on public forums! – Telegram Group
Manage Telegram’s free unlimited storage with a Windows app – Telegram Group
IKIA — Next Gen Metaverse and NFT – Official Ikia – Medium – Telegram Group
More than 60 Telegram channels blocked in Germany – Gagnoncharlotte – Medium – Telegram Group
Using Github Actions, Python and Telegram to Get Ribeye Specials – Telegram Group
How to Install and Run the Crypto-Telegram Bot – Telegram Group
How Telegram Makes Money? Telegrams New Plan to Generate Cash – Telegram Group
How I made +25% in few hours with the help of trading bot! – Telegram Group
Monitoring Ethereum Wallets with Python & Telegram – Telegram Group